CBC Padding Oracle
Cryptopals Set 3 Challenge 17 // code repo // demo
Step 0: Learn What’s Going On, v. High-Level
It is easy to get tripped up on the fact that CBC plaintexts are “padded”. Padding oracles have nothing to do with the actual padding on a CBC plaintext. It’s an attack that targets a specific bit of code that handles decryption. You can mount a padding oracle on any CBC block, whether it’s padded or not.
The hint for this challenge is key! What you’re doing is taking blockSize chunks of ciphertext, making the decryption function think that they are the last block, and then making the padding removal function think they are padded. By making guesses and observing when the padding oracle says that the message has valid padding, you can determine the plaintext without ever seeing decryption output.
Remember in the last challenge how we could manipulate the ciphertext to make the plaintext say whatever we’d like? In that case, we knew both the plaintext and the ciphertext.
In this challenge, we know only the ciphertext. With just this information, plus a way to know whether a message has valid padding (the Padding Oracle!), we can recover the plaintext.
Two adjacent blocks in Cipher Block Chaining mode constitute a complete encryption of a 16-byte plaintext block, so we only need to work with two blocks at a time. This enables us to extend the technique over multiple blocks by taking blockSize*2-sized slices of the ciphertext, moving forward one block at a time, and solving the first block in each slice.
We can solve all blocks except the first without knowing the encryption key or initialization vector (IV). If we have the IV, we can also solve the first block by solving a “first block” of the IV prepended to C1.
In the decryption diagram, the lines between blocks and the XOR operations are targeted, not the “encryption” and “decryption” boxes. Guesses are cheap, because the only operation required to check one guess is a few XORs and a decryption.
Step 1: The Padding Oracle
A padding oracle tells us whether or not a plaintext is properly padded. PKCS7 padding specifies that the end of a plaintext is padded with N bytes of value N so that the block becomes a multiple of blockSize. When we decrypt, we do not want these extra bytes, so often a function looks at the last byte of the last block and chops that number of bytes off the end of the decryption result.
This function doesn’t want to chop something that’s not properly padded. For instance, a block ending in 04 04 01 04 is invalid padding. It says: “chop off the last 4 bytes, each of which are 04”, but one of the bytes isn’t 04. This could just be a message that ends in 04 04 01 04, but it’s not padding. By the way, to eliminate this ambiguity:
- if a message is a multiple of
blockSize, PKCS7 still “pads out” with a block of 16 0x10s
Anyway, the padding removal function throws an error, because this isn’t padding. We use the presence/absence of this error to tell us when we’ve guessed the right byte in the plaintext.
Step 2: How? The Last Byte Shall Be (Found) First
We start by slicing blocks 2 and 3 of the ciphertext. Call these C1 and C2. In decrypting the plaintext from block C2, the result of C2’s decryption gets XOR’d with block C1, and then we chop the padding.
We manipulate C1. Here is a beautiful picture.
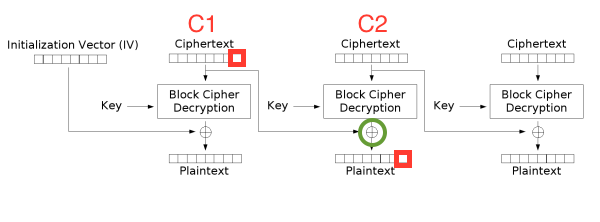
If we change C1[15] (red square), it alters plaintext P[15] (red square).
We will guess all possible values from 0 to 255 for the plaintext byte. There will be valid padding in the result when the last byte equals 0x01. We can use the fact that anything XOR’d with itself is zero. So we do the following operation:
for i=0;i<256;i++) {
- Construct a padded first block of all zeroes except the last position
- This could just be random bytes. Doesn’t matter. It just puts our guess at the last byte of C1.
- Insert our guess of
parseInt(i,10).toString(16)into the last byte of this block
- We do so by XORing the guess with the last byte of C1 (red square!)
- Then we XOR this byte with (0x01), the “valid padding”
- Concatenate our padded first block with C2
- Pass it into our decryption function & see if we get valid plaintext padding (red square ==
0x01)
- If so, store the character
- If not
i++and continue guessing
}
I use the smartIter values from a previous challenge to make smarter guesses and save loop cycles see more here.
We know whether or not we have valid padding by using a try/catch block inside the for loop:
try {
q = empty
.slice(15 - b)
.concat(
hexPad(
hexXOR(hexXOR(char, nB[b]), hP)),
middleMen, nB.slice(16)
);
decrypt = aesDecryptCBC(q, rKey, rIV, 16);
chopped = chopPKCS7(decrypt);
intermediates.unshift(char);
} catch (err) {}
If chopPKCS7 throws an error, the try block breaks early and proceeds to catch. In this case, we don’t care about the error (we know what it is), so we do nothing and continue. If chopPKCS7 succeeds, it means padding is valid, so we store the result in intermediates.
Step 3: Super Verbose Explanation of The Process
We’re creating a situation where if we guess the byte, the output is correctly padded. That’s all.
The tricky part for me was how to do this. Particularly Step #2, where we XOR our guess into the block.
Think about the encryption. When Pn[15] was encrypted, it was XOR’d with Cn-1[15], the encryption result of the last byte of the previous block, and then run through the AES encryption process.
When it is decrypted, the same process happens in reverse. Cn[15] runs through AES decryption. Then it will be XOR’d with the last byte of the previous block of ciphertext, Cn-1[15].
We can make this decryption output visible through the padding oracle side-channel by adding (XOR-ing) two additional pieces of information to Cn-1[15]:
- We XOR our guess for the plaintext byte.
- We XOR valid block padding, given the byte we are guessing:
blockLength - byteIndex.
In this case, to guess Pn[15], we want to modify Cn-1[15] such that when it is decrypted, it gives 0x01 (blockLength:16, byteIndex:15). That’s what this code is doing hexXOR(hexXOR(char,nB[b]),hP):
charis the guess, from 0-255,hPis the padding characternB[b]is the original ciphertext value at index b.
If we guess the correct plaintext byte, we get 0x00 when our guess is XOR’d with the plaintext decryption result. A XOR A == 0. Then, we XOR the padding byte, 0x01. 0x00 XOR 0x01==0x01. So if we guess correctly, we get 0x01, which is valid padding for one byte at the end of a string.
The padding function chops it and does not error. We store the guess as correct. Done!
Step 4: Now Just Iterate! Except…
Well…if we guess wrong, we almost certainly get something that’s not valid padding. It is possible (though rare) that we could guess wrong and still have valid padding. Can you see how this might happen? The description touches on this:
02h 02h is valid padding, but is much less likely to occur randomly than 01h. 03h 03h 03h is even less likely.So you can assume that if you corrupt a decryption AND it had valid padding, you know what that padding byte is.
Imagine the plaintext ends 0x02 0x04. We guess 0x07. 0x07 XOR 0x01 XOR 0x04 = 0x02. The block ends in 0x02 0x02: valid padding. It gets chopped, but we guessed the wrong value. Oops.
We can’t check the length of the decryption result to figure out that it’s sliced off two bytes instead of one. All we know is that it saw 0x02 0x02. That’s valid, so we assume our guess was valid too.
Limitations of the Method
-
These “collisions” happen rarely enough that in most cases, if the padding we engineer into the plaintext is valid, our guess for that byte is also valid.
-
The first block of the plaintext cannot be recovered without knowing the Initialization Vector.
- We XOR our guesses for the bytes of Pn into the Cn-1 block, but for ciphertext block 1, Cn-1 is the IV, which is XOR’d into Block 1, not contained in its own separate block.
Also remember: the result of everything we are doing is directed only toward the XOR after the decryption of C2. Just like with the last challenge, this modification totally jumbles the plaintext output of block #1, but we don’t care. We’re solving block #2. That’s why we iterate through chunks of blockSize*2 but proceed forward one block at a time.
Step 5: Given This Limitation, Iterate to Solve the Block
We save the value of each correct guess, working right-to-left on each byte of the block.
I used Array.unshift (Docs) instead of .push(), since I’m solving the block from right-to-left but the answers I get are read left-to-right. .unshift() puts new elements at the beginning of the array rather than the end like .push(). Last-in => front-of-the-line, instead of last-in => end-of-the-line.
Basically you want some way of storing your intermediate solved characters, because each time you try to guess the next character (one ‘left’, since we’re working right-to-left) of the block, you’ll need to append to your guess your previous correct guesses, each of which are XOR’d with their corresponding value in the ciphertext block, and then XOR’d with the current padding character.
let hP = hexPad(parseInt(16 - b, 10).toString(16));
let middleMen = intermediates.map((e, idx) =>
hexXOR(hexXOR(e, nB[16 - intermediates.length + idx]), hP)
);
Indexing the loop on the byte you’re solving and running from b=15 to 0, r-to-l, is one way to do it.